Let me introduce you to this wonderful tool that can be used in your web archaeology travels: The Internet Archive’s Wayback Machine.

The Wayback Machine is a digital archive of the World Wide Web, and has been archiving versions of websites since 1996. Sadly, we may have already lost much of the early web: sites launched between August 6th, 1991 and May 10th, 1996, as well as websites that were never archived. But let’s focus on what we do have.
It officially launched on May 12th, 1996. The oldest website in the archive seems to be Microsoft on May 10th, 1996.

web.archive.org/web/19960510144231/http://www.microsoft.com/ie/IE.HTM
Aside from some broken images, the Wayback Machine is still a great resource.
Searching for a site in the archive brings you to a calendar view of that website, that gives you a listing of the years and dates of when the website was captured.

The Wayback Machine sitemap view lets you see an overview of the files that are archived.

Some archived sites are in better condition than others. For example, on this page in one of the versions of my old portfolio site (2000-2005), the next button image is missing, and is replaced by text, but the page is otherwise complete.
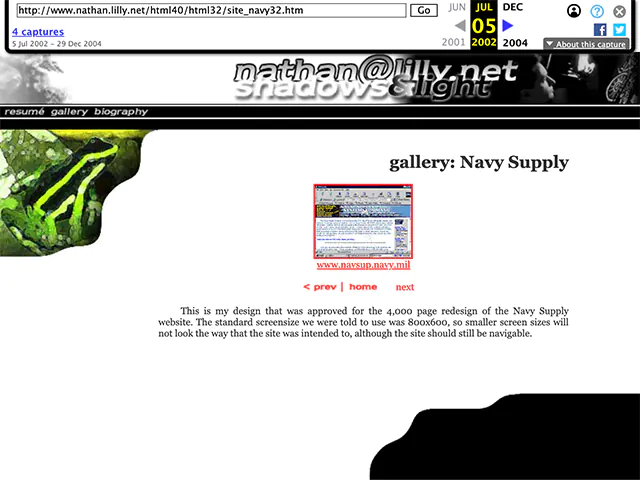
There are whole sections of the website that weren’t archived because they were unintentionally hidden behind JavaScript redirects (to take advantage of the latest browsers), which the archive crawler was not adapted to address.
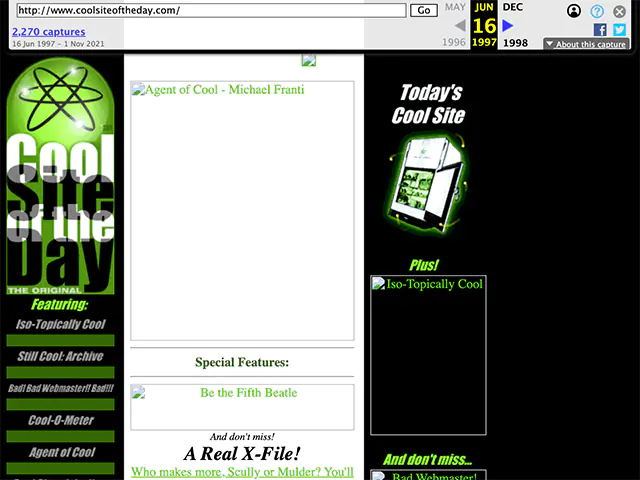
Other sites haven’t faired much better. The Cool Site of the Day website is, regrettably missing several important images.
Occasionally, though, you’ll find gems, like the Star Wars website from 1997, in its entirety.

In 1997, the Star Wars site was objectively parsecs ahead of every other site on the Web at the time and it’s amazing to see a complete page archived in this state – I’m still geeking out about it.
But, the biggest benefit is that if you have the link to an article from a long time ago, it may be possible to find it in the archive. Broken URLs have always been a problem online. In 1996 Keith Shafer and several others proposed a solution to the problem. In a fit of irony, the link to the proposal, Introduction to Persistent Uniform Resource Locators, is now broken. It’s luckily preserved on the Internet Archive’s Wayback Machine:
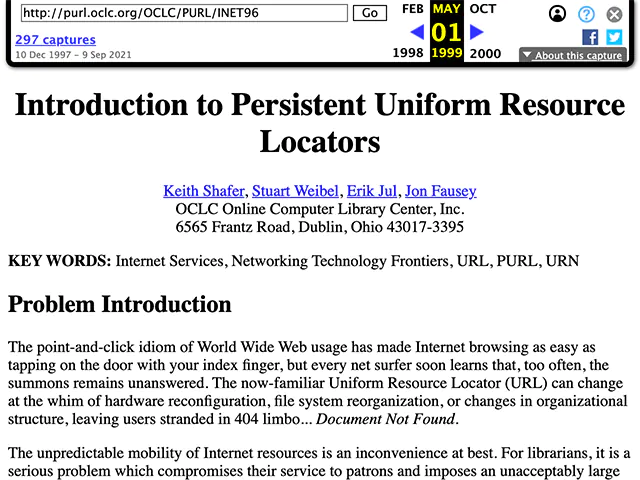
Ideally the solution is creating PURLs, peer-to-peer web hosting, or building the distributed web. In the meantime this is the best we have.